How Mercateo is Rolling Out a Modern Data Platform
Our approach for reducing data issues by a factor of 5, and our lead times for dashboards & reports by a factor of 10.
(View this post also on the Mercateo blog.)

Between 2017–2020 Mercateo underwent some serious changes, as a result, both the data needs and the data landscape inside the company changed a lot.
Data was suddenly becoming increasingly more important to make decisions. A holistic view of the whole business and customer life cycle was suddenly needed. Oh, and on the technology side, everything moved to the cloud and morphed into a micro-service architecture.
Sounds like a major change for the data department? We felt so as well. So we decided to make a few major adjustments, to not only catch up,
but get in front of this changing landscape.
I’ll walk you through what we figured out, the fundamental underlying problem was, and our three-step process to make our data platform resilient and ready for more future changes.
The Fundamental Problem
Mercateo moved from a monolithic to a micro-service architecture in 2017. Before that, we had a good data architecture relying on standard interfaces inside the monolith and a central collection library for additional data.
But the circumstances changed, so we had to reinvent the old architecture. Instead of one big source to query, the data team suddenly had 20+ different sources to ingest data from. The old system was great for
taking in a few selected sources, but not this kind of variety.

On the business side, we moved to a network-based model with Unite, increasing both our product portfolio depth as well as the domains we have inside our company. This also led the perspective to shift from a siloed perspective to one that spans all products and the whole customer lifecycle.
To sum it up:
- the number of data sources exploded
- the number of domains exploded
- suddenly we needed to have data across all products, not just siloed product-specific data.
This alone is just the base, the problems that resulted were:
- Exploding lead times to add new data sources
- Exploding lead times to create new reports & dashboards,
- A lowering level of data quality inside our system.
Of course, this only concerned the new parts of our system, the new requirements, but it’s the part that increasingly became important due to the business shift.
Our Three-Step Process
To make our data structures future-proof, we decided to tackle each of these problems on its own. Starting in 2019, we picked a fight with each one of these problems.
We started with the data quality topic and then focussed on the other two problems by launching two initiatives in parallel. Let’s take a look at each of them in detail.
At the beginning of 2019, our team was mostly providing reports, dashboards & OLAP cubes as a service to different departments across Mercateo. Reports & dashboards in data silos. But that slowly changed.
Step 1: Move to the Cloud

Data Quality on its own is never a leading indicator, it lags behind two things, the time it takes to fix something when it’s broken, and how often developers are able to change things. We realized, that our legacy system was making it hard for the developers to do any development work at all. So we quietly started an initiative.
In 2019, we spent most of our time working inside our legacy system.
But at the beginning of 2020, we decided to use the “strangler pattern” to migrate to the cloud. We simply developed everything new in AWS. That meant it took a little bit longer in the beginning, but slowly, piece by piece, and OLAP cube by OLAP cube, we built up a whole new data architecture.
The small added cost it took to migrate piece by piece wasn’t a big problem, because it was outweighed by the new and much more important domains we tackled. The new cubes we built didn’t focus on silos anymore, they were focused on our new business, overarching products, and thus had a lot more value than the ones we created before.
This made a huge difference in data quality.
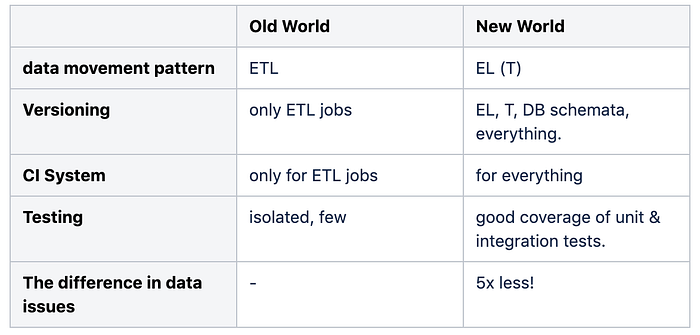
Where our old system was based on ETL and had little testing in place, our new data architecture uses an EL (T) approach, where we load all raw data, and then use the power of our data warehouse to transform it with a specific transformation only tool (we use dbt for that). We integrated our data architecture into a CI system
and automatically deploy schema changes, we test thoroughly and as a result are now able to develop much faster, fix things when they break and were
able to cut down our data failures by a factor of 10.
But that wasn’t the end of it, our new EL (T) pattern enabled something else. Because after increasing our development speed, we still were miles away
from good lead times. So we tackled the problems of “exploding domains”. Basically, the problem was, that inside this analytics team, no one knew his way around what an “order status 4” or a “customer in segment XSD” was. But people outside did!
Step 2: Move to Analytics Engineering
Lacking domain knowledge inside the data team is a very common problem and it already has a solution, one we just couldn’t implement before. Basically, we chose to stop implementing
logic that turned “order status 4” into “order canceled”. Instead, we now let people who actually are inside the domain do the job. Decoupling these “business heavy transformations”
from the data ingestion is called analytics engineering, to distinguish it from the ingestion & the heavy lifting needed to run a data warehouse and everything around it.
Aside from the organizational shift, which meant finding people who are willing to help the company deliver reports, dashboards & analyses much faster,
it also meant we had to actually launch a new BI tool that allows for analytics engineering.
We chose redash, but will move on to an enterprise-level solution in the near future. Still, even using redash we were able to cut down the lead time
on new reports on existing data from months to just a few weeks.

Of course, it still is important that we centrally provide some things, including:
- Testing frameworks, the modeling framework, basically everything an analytics engineer needs to work
- a set of core data pieces
- lots of new raw data!
- the infrastructure that makes it easy to then view the data like the BI tools, but more is still to come.
To facilitate the work between central & decentralized actors we chose a simple model:
- Core data sets are maintained by analytics and showcase best practices
- best practices are published by analytics
- decentralized analytics engineers model in their separate database schema
- Decentralized analytics engineers can set pull requests on any core data set which is swiftly reviewed and deployed if reasonable.
One problem remained. Lead time on existing data was reduced, but the lead time on taking on new data sources was not going down by much. We had freed up some time,
but the micro-services architecture still made it hard.
Step 3: Enter the Customer Journey Tracking

We realized in the beginning, that certain pieces of data were hard to get by. The ones that were now becoming the key aspect of our business, everything related
to growing our network. So we envisioned a new product to help us. It’s coined Customer Journey Tracking and basically is a “PushNServe-as-a-Service” product.
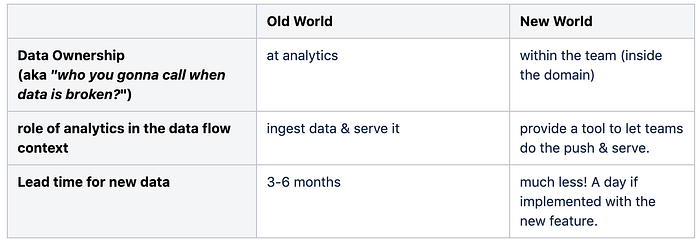
In the previous world, the analytics team would go and “ingest data”, then transform it and serve it to the end-users.
In the Customer Journey Tracking world, the analytics team just provides a pipe. A pipe other teams can push already slightly transformed data into that then gets
served in a variety of standard reports. These standard reports focus on Mercateos key concepts. Very much like Google Analytics Event tracking, just for network-oriented B2B companies.
That’s the end of it?
Work in Progress!
Of course not, we’re still in progress on all three topics. The new data architecture inside analytics is still waiting to get much deeper testing of live data, even though we already have good unit test coverage. Live data testing means adopting a philosophy close to the DataOps ideas and
implement tools like great_expectations. Our new data architecture is still looking for a proper enterprise-level BI tool and once we got that down, we will start focusing on getting the BI adoption rate up in the company. That will very likely involve the deployment of a data catalog and something like a data literacy program e.g. following some of the ideas at HelloFresh.
On the Customer Journey Tracking side, it means further improvements to get more teams and more data onboard, enabling more data
types and very soon also enable pushing this kind of data to other systems, not just the standard set of reports.
Oh, and even though we work almost 95% of the time in our new system, and all feature development happens there, the legacy system
still needs migration. But we’re confident that using the Strangler Pattern we will also resolve that problem sometime in the future, piece
by piece.
